init cyy mind
This commit is contained in:
1
.obsidian/app.json
vendored
Normal file
1
.obsidian/app.json
vendored
Normal file
@@ -0,0 +1 @@
|
||||
{}
|
||||
3
.obsidian/appearance.json
vendored
Normal file
3
.obsidian/appearance.json
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
{
|
||||
"theme": "obsidian"
|
||||
}
|
||||
33
.obsidian/core-plugins.json
vendored
Normal file
33
.obsidian/core-plugins.json
vendored
Normal file
@@ -0,0 +1,33 @@
|
||||
{
|
||||
"file-explorer": true,
|
||||
"global-search": true,
|
||||
"switcher": true,
|
||||
"graph": true,
|
||||
"backlink": true,
|
||||
"canvas": true,
|
||||
"outgoing-link": true,
|
||||
"tag-pane": true,
|
||||
"footnotes": false,
|
||||
"properties": false,
|
||||
"page-preview": true,
|
||||
"daily-notes": true,
|
||||
"templates": true,
|
||||
"note-composer": true,
|
||||
"command-palette": true,
|
||||
"slash-command": false,
|
||||
"editor-status": true,
|
||||
"bookmarks": true,
|
||||
"markdown-importer": false,
|
||||
"zk-prefixer": false,
|
||||
"random-note": false,
|
||||
"outline": true,
|
||||
"word-count": true,
|
||||
"slides": false,
|
||||
"audio-recorder": false,
|
||||
"workspaces": false,
|
||||
"file-recovery": true,
|
||||
"publish": false,
|
||||
"sync": true,
|
||||
"bases": true,
|
||||
"webviewer": false
|
||||
}
|
||||
22
.obsidian/graph.json
vendored
Normal file
22
.obsidian/graph.json
vendored
Normal file
@@ -0,0 +1,22 @@
|
||||
{
|
||||
"collapse-filter": true,
|
||||
"search": "",
|
||||
"showTags": false,
|
||||
"showAttachments": false,
|
||||
"hideUnresolved": false,
|
||||
"showOrphans": true,
|
||||
"collapse-color-groups": true,
|
||||
"colorGroups": [],
|
||||
"collapse-display": true,
|
||||
"showArrow": false,
|
||||
"textFadeMultiplier": 0,
|
||||
"nodeSizeMultiplier": 1,
|
||||
"lineSizeMultiplier": 1,
|
||||
"collapse-forces": true,
|
||||
"centerStrength": 0.518713248970312,
|
||||
"repelStrength": 10,
|
||||
"linkStrength": 1,
|
||||
"linkDistance": 250,
|
||||
"scale": 0.7132754626224403,
|
||||
"close": true
|
||||
}
|
||||
213
.obsidian/workspace.json
vendored
Normal file
213
.obsidian/workspace.json
vendored
Normal file
@@ -0,0 +1,213 @@
|
||||
{
|
||||
"main": {
|
||||
"id": "a3e106b31d1f6389",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "6480f345acaae06e",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "61794e0c5a3743ba",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "markdown",
|
||||
"state": {
|
||||
"file": "个人日记/2026.3.8.md",
|
||||
"mode": "source",
|
||||
"source": false
|
||||
},
|
||||
"icon": "lucide-file",
|
||||
"title": "2026.3.8"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "vertical"
|
||||
},
|
||||
"left": {
|
||||
"id": "f773b158d86aff62",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "b0ebe2b5e21fa881",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "56eebd16a547bbff",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "file-explorer",
|
||||
"state": {
|
||||
"sortOrder": "alphabetical",
|
||||
"autoReveal": false
|
||||
},
|
||||
"icon": "lucide-folder-closed",
|
||||
"title": "文件列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "3a285e81a23285d7",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "search",
|
||||
"state": {
|
||||
"query": "",
|
||||
"matchingCase": false,
|
||||
"explainSearch": false,
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical"
|
||||
},
|
||||
"icon": "lucide-search",
|
||||
"title": "搜索"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "e2ff76d624c81851",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "bookmarks",
|
||||
"state": {},
|
||||
"icon": "lucide-bookmark",
|
||||
"title": "书签"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "horizontal",
|
||||
"width": 690.5
|
||||
},
|
||||
"right": {
|
||||
"id": "6885019000198f8c",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "55c7f3ef5fef319d",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "28309c37e4096893",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "backlink",
|
||||
"state": {
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical",
|
||||
"showSearch": false,
|
||||
"searchQuery": "",
|
||||
"backlinkCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-coming-in",
|
||||
"title": "反向链接"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "3f525cf18f87e3cd",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outgoing-link",
|
||||
"state": {
|
||||
"linksCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-going-out",
|
||||
"title": "出链"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "6b06b5c219b6c11b",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "tag",
|
||||
"state": {
|
||||
"sortOrder": "frequency",
|
||||
"useHierarchy": true,
|
||||
"showSearch": false,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-tags",
|
||||
"title": "标签"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "46b3498093121e31",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outline",
|
||||
"state": {
|
||||
"followCursor": false,
|
||||
"showSearch": false,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-list",
|
||||
"title": "大纲"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "horizontal",
|
||||
"width": 300,
|
||||
"collapsed": true
|
||||
},
|
||||
"left-ribbon": {
|
||||
"hiddenItems": {
|
||||
"bases:新建数据库": false,
|
||||
"switcher:打开快速切换": false,
|
||||
"graph:查看关系图谱": false,
|
||||
"canvas:新建白板": false,
|
||||
"daily-notes:打开/创建今天的日记": false,
|
||||
"templates:插入模板": false,
|
||||
"command-palette:打开命令面板": false
|
||||
}
|
||||
},
|
||||
"active": "61794e0c5a3743ba",
|
||||
"lastOpenFiles": [
|
||||
"零碎的知识/ros1禁用gazebo的gpu功能.md",
|
||||
"个人日记/2026.3.8.md",
|
||||
"个人日记",
|
||||
"零碎的知识/ppo算法.md",
|
||||
"零碎的知识/nginx配置.md",
|
||||
"零碎的知识/ubuntu设置swap交换内存.md",
|
||||
"零碎的知识/win11激活.md",
|
||||
"零碎的知识/vscode免密.md",
|
||||
"零碎的知识/git备忘.md",
|
||||
"零碎的知识/git快捷指令.md",
|
||||
"零碎的知识/clould code.md",
|
||||
"零碎的知识/设置ipv4自动设置.md",
|
||||
"零碎的知识/数学建模导论 -2025年2月学习笔记.md",
|
||||
"零碎的知识/bashrc中设置宏定义.md",
|
||||
"零碎的知识/ubuntu新建用户.md",
|
||||
"fusion实验记录/实验对比.md",
|
||||
"fusion实验记录/D0D85410",
|
||||
"fusion实验记录/CBA93410",
|
||||
"fusion实验记录/F0C73410",
|
||||
"fusion实验记录/95053410",
|
||||
"fusion实验记录/62D13410",
|
||||
"fusion实验记录/F1013410",
|
||||
"fusion实验记录/51013410",
|
||||
"fusion实验记录/3FF03410",
|
||||
"fusion实验记录/CEF03410",
|
||||
"零碎的知识/eda踩雷记录.md",
|
||||
"零碎的知识/设置代理.md",
|
||||
"零碎的知识/嵌入式实验室设备使用指南.md",
|
||||
"c板常用接口.md",
|
||||
"演示.md",
|
||||
"未命名.md",
|
||||
"个人总纲和进度监督/DEADLINE.md",
|
||||
"创建链接.md",
|
||||
"欢迎.md",
|
||||
"未命名 1.md",
|
||||
"Pasted image 20260204203012.png",
|
||||
"Pasted image 20260205113421.png",
|
||||
"Pasted image 20260205113522.png",
|
||||
"Pasted image 20260205113541.png",
|
||||
"Pasted image 20260205113442.png",
|
||||
"Pasted image 20260205113634.png"
|
||||
]
|
||||
}
|
||||
BIN
Pasted image 20260204203012.png
Normal file
BIN
Pasted image 20260204203012.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 76 KiB |
BIN
Pasted image 20260205113421.png
Normal file
BIN
Pasted image 20260205113421.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 23 KiB |
BIN
Pasted image 20260205113442.png
Normal file
BIN
Pasted image 20260205113442.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 23 KiB |
BIN
Pasted image 20260205113522.png
Normal file
BIN
Pasted image 20260205113522.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 54 KiB |
BIN
Pasted image 20260205113541.png
Normal file
BIN
Pasted image 20260205113541.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 25 KiB |
BIN
Pasted image 20260205113634.png
Normal file
BIN
Pasted image 20260205113634.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 24 KiB |
7
c板常用接口.md
Normal file
7
c板常用接口.md
Normal file
@@ -0,0 +1,7 @@
|
||||
![[Pasted image 20260204203012.png]]
|
||||
|
||||
## PWM
|
||||
|
||||
![[Pasted image 20260205113522.png]]
|
||||
![[Pasted image 20260205113541.png]]
|
||||
![[Pasted image 20260205113634.png]]
|
||||
BIN
fusion实验记录/260225实验验记录.xlsx
Normal file
BIN
fusion实验记录/260225实验验记录.xlsx
Normal file
Binary file not shown.
136
fusion实验记录/实验对比.md
Normal file
136
fusion实验记录/实验对比.md
Normal file
@@ -0,0 +1,136 @@
|
||||
|
||||
# 实验对比
|
||||
|
||||
## 2026.02.25
|
||||
|
||||
### 训练yaml
|
||||
|
||||
```yaml
|
||||
'experiment' :
|
||||
|
||||
# 'path_dataset' : '/mnt/data/cdy/project/dataset/FUSION'
|
||||
# 'path_result': '/mnt/data/cdy/data2/results/FUSIONLCD'
|
||||
|
||||
# 'path_dataset' : 'E:\work\Project\dataset\FUSION'
|
||||
# 'path_result' : 'E:\work\Project\results\FUSIONLCD\bev2'
|
||||
|
||||
'path_dataset' : '/home/adlab36/chenyouyuan/FUSIONLCD'
|
||||
'path_result': '/home/adlab36/chenyouyuan/FUSIONLCD/result'
|
||||
'train_flag' : 1
|
||||
'validate_flag' : 0
|
||||
'test_flag' : 0
|
||||
'flag' : 'fusion'
|
||||
'cuda' : 1
|
||||
# TRAINING
|
||||
'epochs' : 200
|
||||
'batchsize' : 6
|
||||
'learning_rate' : 1.e-3
|
||||
'beta1' : 0.9
|
||||
'beta2' : 0.999
|
||||
'eps' : 1.e-8
|
||||
'weight_decay' : 5.e-6
|
||||
'load_model' : 0
|
||||
#FUSION
|
||||
# 'last_model' : '/data4/caodanyang/results/FUSIONLCD/08310/models/checkpoint_079.pth.tar'
|
||||
#BEV
|
||||
# 'last_model' : '/data4/caodanyang/results/FUSIONLCD/bev_09030/models/checkpoint_066.pth.tar'
|
||||
#BEV+EP
|
||||
'last_model' : '/home/adlab36/chenyouyuan/FUSIONLCD/result/log/models/checkpoint_199.pth.tar'
|
||||
#DATASET
|
||||
'train' : 0,5,6,7,9
|
||||
'validate' : 8,50,54,55,56,59
|
||||
'test' : 8,50,54,55,56,59
|
||||
'voxel_num' : 15000
|
||||
'voxel_max_points' : 100
|
||||
'voxel_sample' : 'top'
|
||||
# 'bev_range' : -51.2,-51.2,-2.5,51.2,51.2,1.5
|
||||
# 'bev_resolution' : 0.16
|
||||
# 'bev_range' : -64,-64,-2.5,64,64,1.5
|
||||
# 'bev_resolution' : 0.2
|
||||
'bev_range' : -32,-32,-2.5,32,32,1.5
|
||||
'bev_resolution' : 0.2
|
||||
|
||||
# NETWORK PARAMS
|
||||
'kpts_number_bev' : 150
|
||||
'kpts_number_img' : 0
|
||||
'cluster_num_bev' : 16
|
||||
'cluster_num_img' : 0
|
||||
'cluster_num_fusion' : 16
|
||||
'sinkhorn_iter' : 5
|
||||
'vlad_size' : 256
|
||||
# LOSS
|
||||
'loop_file' : 'loop_GT_4m'
|
||||
'trip_margin' : 0.5
|
||||
'negetative_selsector' : 'random'
|
||||
```
|
||||
|
||||
### 测验yaml
|
||||
|
||||
```yaml
|
||||
'experiment' :
|
||||
|
||||
# 'path_dataset' : '/mnt/data/cdy/project/dataset/FUSION'
|
||||
# 'path_result': '/mnt/data/cdy/data2/results/FUSIONLCD'
|
||||
|
||||
# 'path_dataset' : 'E:\work\Project\dataset\FUSION'
|
||||
# 'path_result' : 'E:\work\Project\results\FUSIONLCD\bev2'
|
||||
|
||||
'path_dataset' : '/home/adlab36/chenyouyuan/FUSIONLCD'
|
||||
'path_result': '/home/adlab36/chenyouyuan/FUSIONLCD/result'
|
||||
'train_flag' : 0
|
||||
'validate_flag' : 1
|
||||
'test_flag' : 1
|
||||
'flag' : 'fusion'
|
||||
'cuda' : 1
|
||||
# TRAINING
|
||||
'epochs' : 200
|
||||
'batchsize' : 6
|
||||
'learning_rate' : 1.e-3
|
||||
'beta1' : 0.9
|
||||
'beta2' : 0.999
|
||||
'eps' : 1.e-8
|
||||
'weight_decay' : 5.e-6
|
||||
'load_model' : 1
|
||||
#FUSION
|
||||
# 'last_model' : '/data4/caodanyang/results/FUSIONLCD/08310/models/checkpoint_079.pth.tar'
|
||||
#BEV
|
||||
# 'last_model' : '/data4/caodanyang/results/FUSIONLCD/bev_09030/models/checkpoint_066.pth.tar'
|
||||
#BEV+EP
|
||||
'last_model' : '/home/adlab36/chenyouyuan/FUSIONLCD/result/log/models/checkpoint_199.pth.tar'
|
||||
#DATASET
|
||||
'train' : 0,5,6,7,9
|
||||
'validate' : 8,50,54,55,56,59
|
||||
'test' : 8,50,54,55,56,59
|
||||
'voxel_num' : 15000
|
||||
'voxel_max_points' : 100
|
||||
'voxel_sample' : 'top'
|
||||
# 'bev_range' : -51.2,-51.2,-2.5,51.2,51.2,1.5
|
||||
# 'bev_resolution' : 0.16
|
||||
# 'bev_range' : -64,-64,-2.5,64,64,1.5
|
||||
# 'bev_resolution' : 0.2
|
||||
'bev_range' : -32,-32,-2.5,32,32,1.5
|
||||
'bev_resolution' : 0.2
|
||||
|
||||
# NETWORK PARAMS
|
||||
'kpts_number_bev' : 150
|
||||
'kpts_number_img' : 0
|
||||
'cluster_num_bev' : 16
|
||||
'cluster_num_img' : 0
|
||||
'cluster_num_fusion' : 16
|
||||
'sinkhorn_iter' : 5
|
||||
'vlad_size' : 256
|
||||
# LOSS
|
||||
'loop_file' : 'loop_GT_4m'
|
||||
'trip_margin' : 0.5
|
||||
'negetative_selsector' : 'random'
|
||||
```
|
||||
|
||||
### 测验结果
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 与论文对比
|
||||
|
||||
同级目录下表格文件
|
||||
26
个人总纲和进度监督/DEADLINE.md
Normal file
26
个人总纲和进度监督/DEADLINE.md
Normal file
@@ -0,0 +1,26 @@
|
||||
# DEADLINE
|
||||
## 实习
|
||||
|
||||
| 任务 | deadline |
|
||||
| ----------- | ----------- |
|
||||
| 起码完成仿真上台阶任务 | 2.13 16点前 |
|
||||
| 完成机器狗实体部署 | 2.14 - 18点前 |
|
||||
| 完成平台机器狗项目迁移 | 2.15 前 |
|
||||
| 周报 | 2.14 -20点 |
|
||||
|
||||
## 论文
|
||||
|
||||
| 任务 | deadline |
|
||||
| --------------- | ------------- |
|
||||
| 理清楚论文代码结构 | 12.12 18点前 |
|
||||
| 迁移数据到新服务器 | 12.12 21:00开始 |
|
||||
| 搞清楚论文提到的一些名词和意义 | none |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
0
个人日记/2026.3.8.md
Normal file
0
个人日记/2026.3.8.md
Normal file
3
零碎的知识/bashrc中设置宏定义.md
Normal file
3
零碎的知识/bashrc中设置宏定义.md
Normal file
@@ -0,0 +1,3 @@
|
||||
```
|
||||
alias clr='clear'
|
||||
```
|
||||
129
零碎的知识/clould code.md
Normal file
129
零碎的知识/clould code.md
Normal file
@@ -0,0 +1,129 @@
|
||||
# claude code使用国内模型教程--从安装到api配置
|
||||
|
||||
## 打开梯子后开启全局模式
|
||||
|
||||
这里使用powershell的winget下载(会自动帮你配置全局变量)
|
||||
|
||||
```
|
||||
winget install Anthropic.ClaudeCode
|
||||
```
|
||||
|
||||
显示已经成功安装后,重新打开终端
|
||||
|
||||
输入下面查询版本,如果正常输出版本,即正常安装
|
||||
|
||||
```
|
||||
claude --version
|
||||
```
|
||||
|
||||
## 配置国内api
|
||||
|
||||
在配置前,请确保清除以下 Anthropic 相关的环境变量,以免影响 其他国产 API 的正常使用:
|
||||
|
||||
- `ANTHROPIC_AUTH_TOKEN`
|
||||
- `ANTHROPIC_BASE_URL`
|
||||
|
||||
设置win用户文件夹下的.claude.json文件
|
||||
在最末尾添加跳过引导的设置
|
||||
|
||||
```json
|
||||
"hasCompletedOnboarding": true
|
||||
```
|
||||
|
||||
举例:
|
||||
|
||||
```json
|
||||
{
|
||||
"numStartups": 2,
|
||||
"tipsHistory": {
|
||||
"new-user-warmup": 1,
|
||||
"plan-mode-for-complex-tasks": 1,
|
||||
"terminal-setup": 2,
|
||||
"memory-command": 2
|
||||
},
|
||||
"firstStartTime": "xxxx",
|
||||
"opusProMigrationComplete": true,
|
||||
"sonnet1m45MigrationComplete": true,
|
||||
"userID": "xxxxxxxxxxx",
|
||||
"clientDataCache": {
|
||||
"data": null,
|
||||
"timestamp": 1772008200935
|
||||
},
|
||||
"cachedChromeExtensionInstalled": false,
|
||||
"hasCompletedOnboarding": true
|
||||
}
|
||||
```
|
||||
|
||||
之后打开你想要运行claude的文件夹,空白处右键,点击open in terminal
|
||||
|
||||
输入
|
||||
|
||||
```
|
||||
claude
|
||||
```
|
||||
|
||||
打开之后
|
||||
|
||||
输入
|
||||
|
||||
```
|
||||
/login
|
||||
```
|
||||
|
||||
选择第三个,使用第三方登录
|
||||
|
||||
之后输入以下指令可以关闭窗口
|
||||
|
||||
```
|
||||
/exit
|
||||
```
|
||||
|
||||
在用户文件夹下找到.claude文件夹
|
||||
|
||||
在该目录下新建settings.json文件
|
||||
|
||||
如下配置即可
|
||||
|
||||
```json
|
||||
# 在.claude编辑或新增 `settings.json` 文件
|
||||
# MacOS & Linux 为 `~/.claude/settings.json`
|
||||
# Windows 为`用户目录/.claude/settings.json`
|
||||
# 新增或修改里面的 env 字段
|
||||
# 注意替换里面的 `your_zhipu_api_key` 为您上一步获取到的 API Key
|
||||
# ANTHROPIC_BASE_URL为服务商api访问入口
|
||||
# ANTHROPIC_AUTH_TOKEN 为你的api_key
|
||||
# "ANTHROPIC_DEFAULT_HAIKU_MODEL": 快速模型,
|
||||
"ANTHROPIC_DEFAULT_SONNET_MODEL": 中等性能模型,
|
||||
"ANTHROPIC_DEFAULT_OPUS_MODEL": 复杂任务处理模型"
|
||||
# 如果只想要使用一种,就直接都填一样的就行,模型名称参考官网
|
||||
{
|
||||
"env": {
|
||||
"ANTHROPIC_AUTH_TOKEN": "your_zhipu_api_key",
|
||||
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
|
||||
"API_TIMEOUT_MS": "3000000",
|
||||
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
|
||||
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
|
||||
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
|
||||
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
模型层级
|
||||
|
||||
Claude Code 将模型分为三个层级:
|
||||
- Haiku - 快速便宜,用于简单查询
|
||||
- Sonnet - 中等性能,用于一般任务
|
||||
- Opus - 最强大,用于复杂任务
|
||||
|
||||
使用方式
|
||||
|
||||
在 Claude Code 中可以用快捷键切换模型:
|
||||
- /h - 使用 Haiku 模型
|
||||
- /s - 使用 Sonnet 模型
|
||||
- /o - 使用 Opus 模型
|
||||
|
||||
配置完成后即可愉快的享用啦
|
||||
|
||||

|
||||
|
||||
2
零碎的知识/eda踩雷记录.md
Normal file
2
零碎的知识/eda踩雷记录.md
Normal file
@@ -0,0 +1,2 @@
|
||||
鼠标指针使用高亮后报错
|
||||
引脚规划器配置错误未清除会导致问题
|
||||
24
零碎的知识/git备忘.md
Normal file
24
零碎的知识/git备忘.md
Normal file
@@ -0,0 +1,24 @@
|
||||
# git备忘
|
||||
|
||||
```
|
||||
git tag
|
||||
git tag -l -n
|
||||
git checkout [branch/tag]
|
||||
```
|
||||
|
||||
|
||||
设置局部提交作者
|
||||
在.git的config下
|
||||
|
||||
[user]
|
||||
|
||||
name = MobKBK
|
||||
|
||||
email = 202311250413@csust.edu.cn
|
||||
|
||||
|
||||
|
||||
git remote add origin
|
||||
|
||||
git remote set-url origin
|
||||
git remot -v
|
||||
2
零碎的知识/git快捷指令.md
Normal file
2
零碎的知识/git快捷指令.md
Normal file
@@ -0,0 +1,2 @@
|
||||
切换tag
|
||||
sudo ifconfig ens33 192.168.1.31 netmask 255.255.255.0
|
||||
1
零碎的知识/nginx配置.md
Normal file
1
零碎的知识/nginx配置.md
Normal file
@@ -0,0 +1 @@
|
||||
nginx -T查看所有配置
|
||||
40
零碎的知识/ppo算法.md
Normal file
40
零碎的知识/ppo算法.md
Normal file
@@ -0,0 +1,40 @@
|
||||
# ppo算法
|
||||
|
||||
[零基础学习强化学习算法:ppo_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1iz421h7gb/?spm_id_from=333.337.search-card.all.click&vd_source=f553a12b04c16a678ddc0064cc04563c)
|
||||
|
||||
<img src="http://tuchuang-cyy.oss-cn-beijing.aliyuncs.com/img/image-20260203074417725.png" alt="image-20260203074417725" style="zoom: 67%;" />
|
||||
|
||||
|
||||
|
||||
<img src="http://tuchuang-cyy.oss-cn-beijing.aliyuncs.com/img/image-20260203074801825.png" alt="image-20260203074801825" style="zoom:80%;" />
|
||||
|
||||
|
||||
|
||||
action space
|
||||
|
||||
|
||||
|
||||
策略policy
|
||||
|
||||
trajectory
|
||||
|
||||
return
|
||||
|
||||
|
||||
|
||||
马尔科夫链
|
||||
|
||||
蒙特卡洛
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
4
零碎的知识/ros1禁用gazebo的gpu功能.md
Normal file
4
零碎的知识/ros1禁用gazebo的gpu功能.md
Normal file
@@ -0,0 +1,4 @@
|
||||
# ros1禁用gazebo的gpu功能
|
||||
|
||||
export OGRE_RENDER_SYSTEM=GL
|
||||
export LIBGL_ALWAYS_SOFTWARE=1
|
||||
4
零碎的知识/ubuntu新建用户.md
Normal file
4
零碎的知识/ubuntu新建用户.md
Normal file
@@ -0,0 +1,4 @@
|
||||
|
||||
|
||||
sudo adduser 新用户名
|
||||
su - 新用户名 切换到这个用户
|
||||
28
零碎的知识/ubuntu设置swap交换内存.md
Normal file
28
零碎的知识/ubuntu设置swap交换内存.md
Normal file
@@ -0,0 +1,28 @@
|
||||
|
||||
|
||||
```
|
||||
# 1. (可选)创建一个目录用于存放Swap文件,或者直接在根目录创建
|
||||
sudo mkdir -p /swapfile_custom_dir
|
||||
cd /swapfile_custom_dir
|
||||
|
||||
# 2. 使用dd命令创建一个指定大小的空文件 (bs=1M表示块大小为1MB, count=1024表示1024个块,即1GB)
|
||||
sudo dd if=/dev/zero of=swap bs=1M count=1024
|
||||
|
||||
# 3. 设置正确的文件权限 (只有root用户可读写)
|
||||
sudo chmod 0600 swap
|
||||
|
||||
# 4. 将该文件格式化为Swap分区
|
||||
sudo mkswap -f swap
|
||||
|
||||
# 5. 启用Swap分区
|
||||
sudo swapon swap
|
||||
|
||||
# 6. 验证Swap空间是否已启用 (会显示Swap总量和已用量)
|
||||
free -h
|
||||
swapon --show
|
||||
# 开机自加载
|
||||
echo '/swapfile_custom_dir/swap none swap sw 0 0' >> /etc/fstab
|
||||
```
|
||||
|
||||
scp的使用
|
||||
scp /本地路径/图片.jpg username@服务器IP:/home/username/images/
|
||||
24
零碎的知识/vscode免密.md
Normal file
24
零碎的知识/vscode免密.md
Normal file
@@ -0,0 +1,24 @@
|
||||
记录
|
||||
|
||||
[【vscode】设置免密码连接远程服务器_vscode免密登陆远程服务器-CSDN博客](https://blog.csdn.net/qq_45956730/article/details/137601010)
|
||||
cmd
|
||||
|
||||
```cmd
|
||||
ssh-keygen
|
||||
找到C:\Users\【用户名】\.ssh\rsa.pub复制
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDH3v5zXryO48qGi929uRz/bx3g/v4d2mPct9MQog8C6n9MbpyCxxCwLVf02YwyR0si9uqnODg76sA7bbj0DpSfgszA2S3XnDzY2iOssH+s3TszSNXLNiA3CJ37pZHN0JpU4mtcf3b7I7fZuiQHzq/7rOa/rKmwnconGsQbUg4NMJChKWNK0sg1JKj7Q2xXy0QlStQPWsCMyiFr/GYz/Bm7nt4lJbPy6NqGH767VWagaPgYHQNEmEpfs9yLrv5YGlbfH/8jK5vM/i4KgCa8P4wYcTi6OGnF6jRfl9T790uzgAQpHnmOsifvdJbpuusYS4rMTGGgNsL+AFcwFpWK2/4hWaHPifM+93FVd/g+IsQHtvedK5ArwRFuRfuVtcGxkWdmTH3OfxXQM6SdCa6d45JIkx4WYBRcYXkI2U8bfP7Tc+xPsWjkPX3d3tmBM0hEjheHO19Eb1az+QnEt2rHaFughNkgyoMEP9uVaWFdBN9GTCEPbcsFn9q4Mi6B8goF2Nk= 32892@cyy
|
||||
|
||||
// 远程
|
||||
mkdir -p ~/.ssh
|
||||
chmod 700 ~/.ssh
|
||||
touch ~/.ssh/authorized_keys
|
||||
chmod 600 ~/.ssh/authorized_keys
|
||||
把密钥粘贴到这里面
|
||||
|
||||
```
|
||||
|
||||
^3e4f15
|
||||
|
||||
ubuntu上没有.ssh文件?
|
||||
进入root文件夹下新建一个
|
||||
|
||||
119
零碎的知识/win11激活.md
Normal file
119
零碎的知识/win11激活.md
Normal file
@@ -0,0 +1,119 @@
|
||||
# win11激活和快速清爽配置
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
## 跳过联网
|
||||
|
||||
shift + f10
|
||||
|
||||
打开命令行窗口
|
||||
|
||||
```cmd
|
||||
start ms-cxh:localonly
|
||||
```
|
||||
|
||||
## 激活账户
|
||||
|
||||
powershell 管理员模式
|
||||
|
||||
输入
|
||||
|
||||
```shell
|
||||
irm https://get.activated.win | iex
|
||||
```
|
||||
|
||||
出现数字时
|
||||
|
||||
输入1
|
||||
|
||||
等待即可,等到弹出press any key
|
||||
|
||||
就完成了激活(需要重新打开设置查看才能看到效果
|
||||
|
||||
## 简洁化配置
|
||||
|
||||
### 设置背景选择图片
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 修改锁屏
|
||||
|
||||
直接在设置的左上角搜索栏搜索锁屏
|
||||
|
||||
|
||||
|
||||
也改成图片
|
||||
|
||||
|
||||
|
||||
### 隐藏组件
|
||||
|
||||
在设置->个性化->任务栏 如下设置
|
||||
|
||||
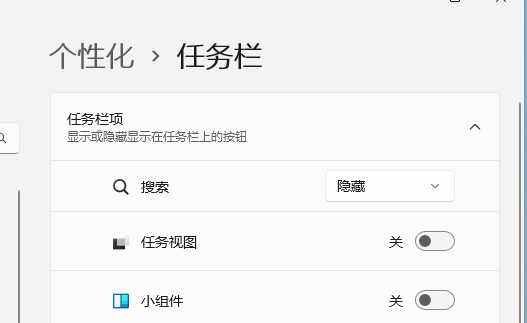
|
||||
|
||||
### 关闭应用自启动
|
||||
|
||||
在设置->应用->启动 中设置如下
|
||||
|
||||
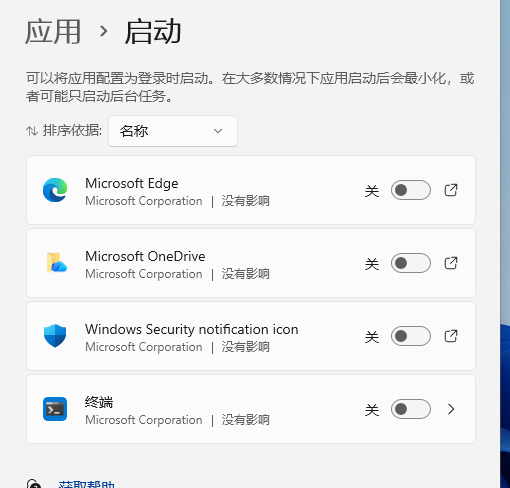
|
||||
|
||||
|
||||
|
||||
## 暂停更新
|
||||
|
||||
按win键,在搜索栏点击搜索power->左侧右键->选择以管理员身份运行
|
||||
|
||||
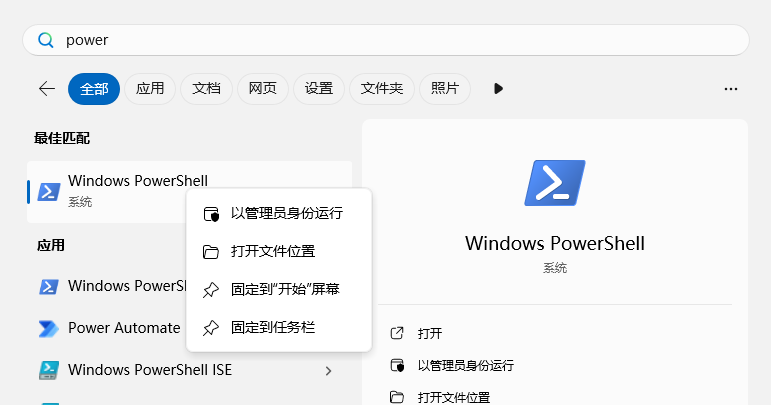
|
||||
|
||||
复制下面这行指令
|
||||
|
||||
```shell
|
||||
reg add "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings" /v FlightSettingsMaxPauseDays /t reg_dword /d 10000 /f
|
||||
```
|
||||
|
||||
右键粘贴到命令行窗口
|
||||
|
||||
回车运行
|
||||
|
||||
之后回到设置里面的更新页面,选择暂停时间,一直拖到最底下选择1000周后再更新
|
||||
|
||||
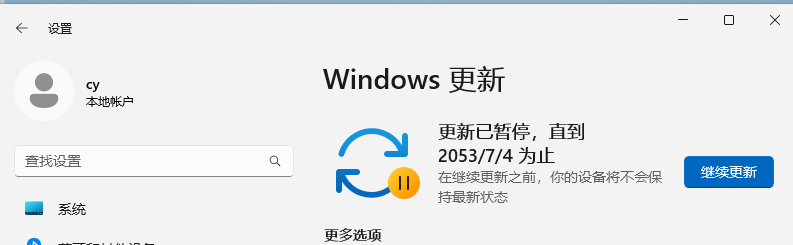
|
||||
|
||||
|
||||
|
||||
## edge配置
|
||||
|
||||
打开edge->右上角的三个点->扩展->获取扩展
|
||||
|
||||
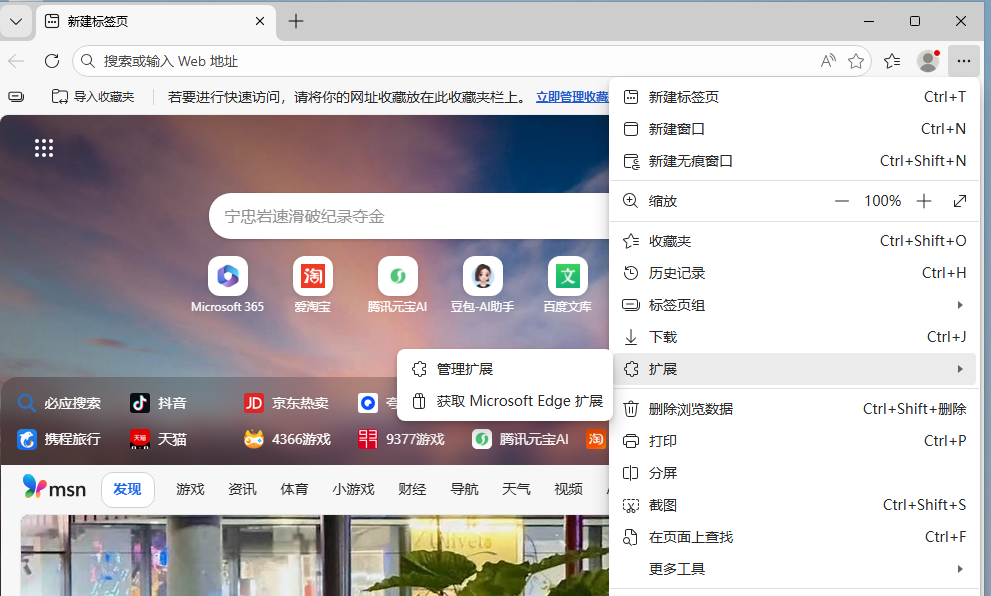
|
||||
|
||||
搜索青柠起始页->获取->添加扩展
|
||||
|
||||
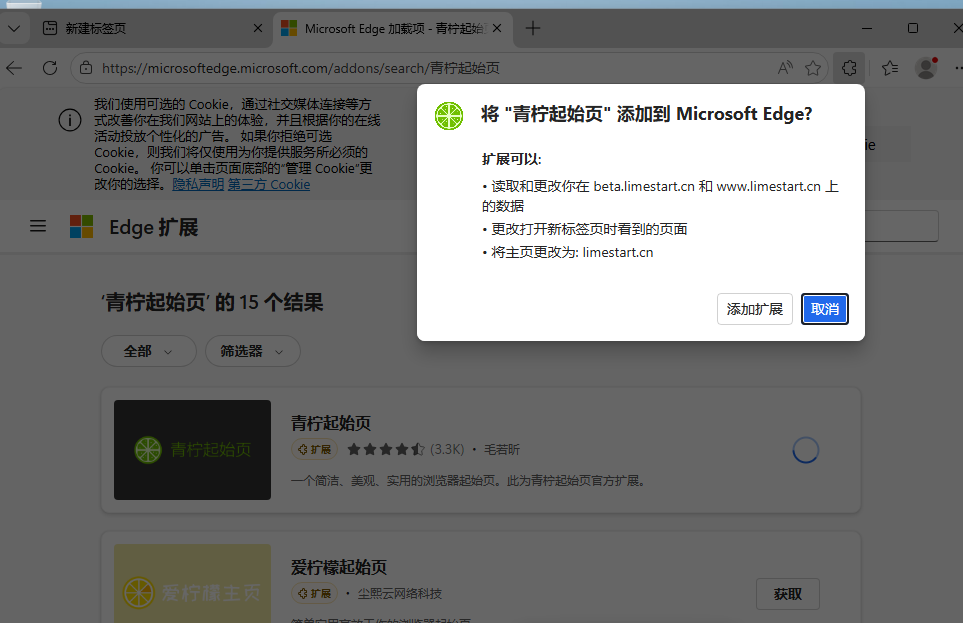
|
||||
|
||||
再回到右上角三个点->扩展->管理扩展
|
||||
|
||||
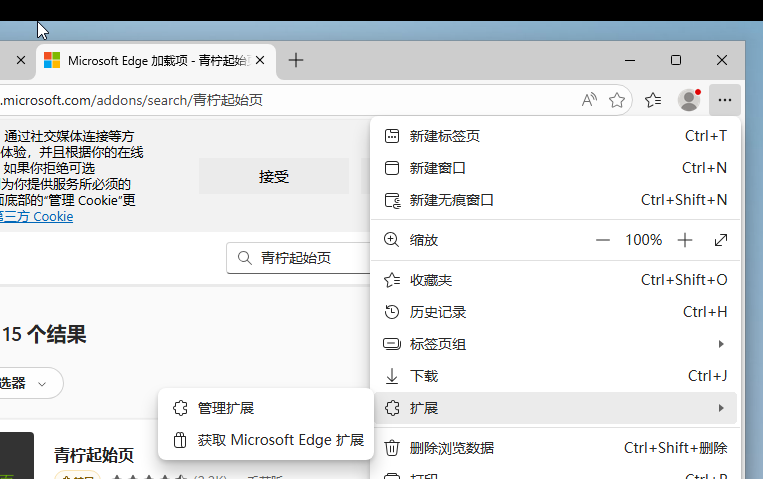
|
||||
|
||||
把启用勾上
|
||||
|
||||
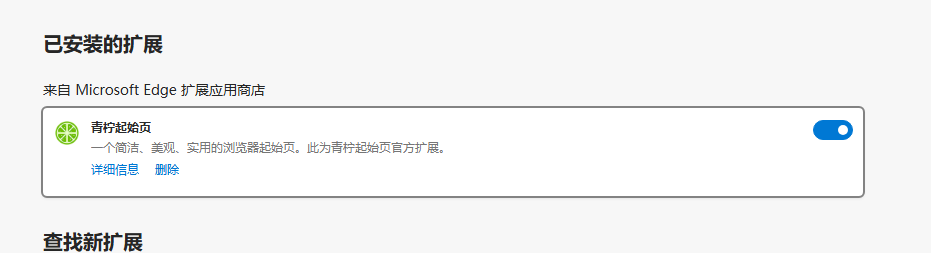
|
||||
|
||||
|
||||
|
||||
在顶部点击加号添加新标签页之后会弹出窗口
|
||||
|
||||

|
||||
|
||||
点击保留更改即可
|
||||
|
||||
|
||||
|
||||
如下图点击左侧图标即可切换搜索引擎,国内搜索推荐使用bing
|
||||
|
||||
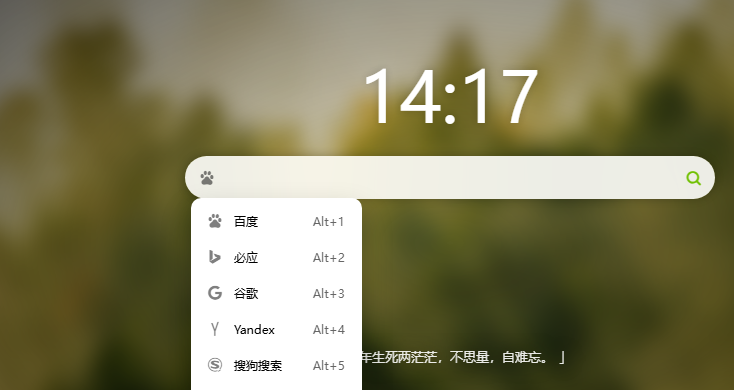
|
||||
51
零碎的知识/嵌入式实验室设备使用指南.md
Normal file
51
零碎的知识/嵌入式实验室设备使用指南.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# 嵌入式实验室设备使用指南--3d打印机篇
|
||||
|
||||
<img src="http://tuchuang-cyy.oss-cn-beijing.aliyuncs.com/img/嵌入式_无背景logo.png" alt="嵌入式_无背景logo" style="zoom:25%;" />
|
||||
|
||||
电脑端需要安装bambu studio:[软件下载 - Bambu Studio | Bambu Lab CN](https://bambulab.cn/zh-cn/download/studio)
|
||||
|
||||
手机端想查看和绑定使用:[软件下载 - Bambu Handy | Bambu Lab CN](https://bambulab.cn/zh-cn/download/app)
|
||||
|
||||
bambu农场(可以尝试串联多台打印机,未使用过):[拓竹农场管家软件快速入门 | Bambu Lab Wiki](https://wiki.bambulab.com/zh/software/bambu-farm-manager)
|
||||
|
||||
官方wiki:
|
||||
|
||||
[主页 | Bambu Lab Wiki](https://wiki.bambulab.com/zh/home)
|
||||
|
||||
|
||||
|
||||
## 3d打印机视频教程(优先看官网教程
|
||||
|
||||
拓竹ai mini:
|
||||
|
||||
[拓竹A1mini全流程10分钟速通(入门)_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV12Uz1YLE9B/?spm_id_from=333.337.search-card.all.click&vd_source=f553a12b04c16a678ddc0064cc04563c)
|
||||
|
||||
拓竹p1s:
|
||||
|
||||
[拓竹3D打印机入门手把手喂饭教程(FDM 3D打印机基本通用)_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV16yiLBNEQt/?spm_id_from=333.337.search-card.all.click&vd_source=f553a12b04c16a678ddc0064cc04563c)
|
||||
|
||||
其余打印机类似
|
||||
|
||||
### 关于维护
|
||||
|
||||
建议每次打印前和打印后都使用酒精清理擦拭板面,去除手指油污,减少炒面概率
|
||||
|
||||
> *** 必看: 优先寻找官方维修教程,凡事官方最为权威,文档解决不了,找客服,最次才是自己去找民间教程。**
|
||||
|
||||
官方wiki:
|
||||
|
||||
[主页 | Bambu Lab Wiki](https://wiki.bambulab.com/zh/home)
|
||||
|
||||
a1mini:[A1 mini | Bambu Lab Wiki](https://wiki.bambulab.com/zh/a1-mini)
|
||||
|
||||
p1s:[P1系列 | Bambu Lab Wiki](https://wiki.bambulab.com/zh/p1)
|
||||
|
||||
[3D打印如何避免炒面?_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1n3SzYkEAt/?spm_id_from=333.337.search-card.all.click&vd_source=f553a12b04c16a678ddc0064cc04563c)
|
||||
|
||||
|
||||
|
||||
# 如果出现问题
|
||||
|
||||
如果打印机出现问题,或者还在维修,或者出现异常,第一时间在大群告诉大家,以免造成不必要的损失
|
||||
|
||||
修复后也及时告知大家
|
||||
371
零碎的知识/数学建模导论 -2025年2月学习笔记.md
Normal file
371
零碎的知识/数学建模导论 -2025年2月学习笔记.md
Normal file
@@ -0,0 +1,371 @@
|
||||
# 数学建模导论 --- pandas的简单使用
|
||||
|
||||
--2025年2月学习笔记
|
||||
|
||||
学习内容摘自[intro-mathmodel-课程详情 | Datawhale](https://www.datawhale.cn/learn/content/85/3136)
|
||||
|
||||
感谢分享!
|
||||
|
||||
学习数学建模更重要的是知道面对不同体量的数据如何快速下手找准最合适的建模方法
|
||||
|
||||
靠山吃山,靠水吃水。小数据有小数据的方法,大数据有大数据的方法。拿着线性回归的那一套去拟合大数据,往往效果不会很好;拿着神经网络去学小数据,学到的东西往往没有意义(我们会笑称:你是想去研究few-shot learning吗)。面对不同的数据,能够使用最合适的方法最为重要。而判断此方法是否合适,一个根本的衡量就是数据的体量。
|
||||
|
||||
## 数据科学的研究对象
|
||||
|
||||
- 数据的获取和存储:包括爬虫、软件定义存储、硬件存储有关背景知识等。
|
||||
- 数据的处理:包括分布式计算、并行计算、数据流等知识,以及Hadoop、Spark等大数据框架。
|
||||
- 数据的分析:包括统计学、数据挖掘与机器学习、计算机视觉、自然语言处理等内容,重在挖掘数据中的模式与知识。
|
||||
- 数据的管理:现代数据库系统及其架构等内容。
|
||||
- 数据的应用:数据可视化、数据相关软件的开发、报表分析以及如何将数据挖掘得到的结果还原为实际问题的解决方案。
|
||||
|
||||
## 使用pandas处理数据的基础
|
||||
|
||||
### 1.环境相关
|
||||
|
||||
这里我使用的是pycharm进行的python编写,环境是用conda建的新环境
|
||||
|
||||
python = 3.10
|
||||
|
||||
```bash
|
||||
# 使用清华镜像源下载更快
|
||||
pip insatll pandas -i https://pypi.tuna.tsinghua,edu.cn/simple
|
||||
```
|
||||
|
||||
### 2.练习一
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
|
||||
# 字典格式
|
||||
data = {'animal': ['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],
|
||||
'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],
|
||||
'visits': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
|
||||
'priority': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
|
||||
|
||||
# 作为索引
|
||||
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
|
||||
|
||||
df = pd.DataFrame(data)
|
||||
|
||||
# 默认输出有数值的统计结果
|
||||
print(df.describe())
|
||||
# age visits
|
||||
# count 8.000000 10.000000
|
||||
# mean 3.437500 1.900000
|
||||
# std 2.007797 0.875595
|
||||
# min 0.500000 1.000000
|
||||
# 25% 2.375000 1.000000
|
||||
# 50% 3.000000 2.000000
|
||||
# 75% 4.625000 2.750000
|
||||
# max 7.000000 3.000000
|
||||
# 计数,均值,标准差,最小值。。。。最大值
|
||||
|
||||
|
||||
# 增加参数即可输出上面的animal和priority
|
||||
print(df.describe(include='all'))
|
||||
# animal age visits priority
|
||||
# count 10 8.000000 10.000000 10
|
||||
# unique 3 NaN NaN 2
|
||||
# top cat NaN NaN no
|
||||
# freq 4 NaN NaN 6
|
||||
# mean NaN 3.437500 1.900000 NaN
|
||||
# std NaN 2.007797 0.875595 NaN
|
||||
# min NaN 0.500000 1.000000 NaN
|
||||
# 25% NaN 2.375000 1.000000 NaN
|
||||
# 50% NaN 3.000000 2.000000 NaN
|
||||
# 75% NaN 4.625000 2.750000 NaN
|
||||
# max NaN 7.000000 3.000000 NaN
|
||||
|
||||
# 输出为数据的前五列
|
||||
print(df.head(5))
|
||||
# animal age visits priority
|
||||
# 0 cat 2.5 1 yes
|
||||
# 1 cat 3.0 3 yes
|
||||
# 2 snake 0.5 2 no
|
||||
# 3 dog NaN 3 yes
|
||||
# 4 dog 5.0 2 no
|
||||
|
||||
|
||||
# 除了最后一列不输出
|
||||
print(df.head(-1))
|
||||
# animal age visits priority
|
||||
# 0 cat 2.5 1 yes
|
||||
# 1 cat 3.0 3 yes
|
||||
# 2 snake 0.5 2 no
|
||||
# 3 dog NaN 3 yes
|
||||
# 4 dog 5.0 2 no
|
||||
# 5 cat 2.0 3 no
|
||||
# 6 snake 4.5 1 no
|
||||
# 7 cat NaN 1 yes
|
||||
# 8 dog 7.0 2 no
|
||||
|
||||
# 打印有动物和age的列
|
||||
print(df[['animal', 'age']])
|
||||
# animal age
|
||||
# 0 cat 2.5
|
||||
# 1 cat 3.0
|
||||
# 2 snake 0.5
|
||||
# 3 dog NaN
|
||||
# 4 dog 5.0
|
||||
# 5 cat 2.0
|
||||
# 6 snake 4.5
|
||||
# 7 cat NaN
|
||||
# 8 dog 7.0
|
||||
# 9 dog 3.0
|
||||
|
||||
# 全部打印
|
||||
print(df)
|
||||
# animal age visits priority
|
||||
# 0 cat 2.5 1 yes
|
||||
# 1 cat 3.0 3 yes
|
||||
# 2 snake 0.5 2 no
|
||||
# 3 dog NaN 3 yes
|
||||
# 4 dog 5.0 2 no
|
||||
# 5 cat 2.0 3 no
|
||||
# 6 snake 4.5 1 no
|
||||
# 7 cat NaN 1 yes
|
||||
# 8 dog 7.0 2 no
|
||||
# 9 dog 3.0 1 no
|
||||
|
||||
# 输出3 4 8行的 animal age
|
||||
print(df.loc[[3, 4, 8], ['animal', 'age']])
|
||||
# animal age
|
||||
# 3 dog NaN
|
||||
# 4 dog 5.0
|
||||
# 8 dog 7.0
|
||||
|
||||
# 输出原有index
|
||||
print(df.index)
|
||||
# RangeIndex(start=0, stop=10, step=1)
|
||||
|
||||
# 更改index
|
||||
df.index = labels
|
||||
print(df.index)
|
||||
# Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'], dtype='object')
|
||||
|
||||
print('改变之前:', df.loc[['f'],['age']])
|
||||
df.loc[['f'], ['age']] = 1.5
|
||||
print('改变之后:', df.loc[['f'],['age']])
|
||||
# 改变之前: age
|
||||
# f 2.0
|
||||
# 改变之后 age
|
||||
# f 1.5
|
||||
|
||||
# 求和
|
||||
print(df['visits'].sum())
|
||||
# 19
|
||||
|
||||
|
||||
print(df.groupby(['animal'])['age'].mean())
|
||||
# animal
|
||||
# cat 2.333333
|
||||
# dog 5.000000
|
||||
# snake 2.500000
|
||||
# Name: age, dtype: float64
|
||||
|
||||
|
||||
```
|
||||
|
||||
### 3.练习二
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
df = pd.DataFrame({'From_To': ['LoNDon_paris', 'MAdrid_miLAN', 'londON_StockhOlm', 'Budapest_PaRis', 'Brussels_londOn'],
|
||||
'FlightNumber': [10045, np.nan, 10065, np.nan, 10085],
|
||||
'RecentDelays': [[23, 47], [], [24, 43, 87], [13], [67, 32]],
|
||||
'Airline': ['KLM(!)', '<Air France> (12)', '(British Airways. )', '12. Air France', '"Swiss Air"']})
|
||||
|
||||
# 打印出来看看df
|
||||
print(df)
|
||||
# From_To FlightNumber RecentDelays Airline
|
||||
# 0 LoNDon_paris 10045.0 [23, 47] KLM(!)
|
||||
# 1 MAdrid_miLAN NaN [] <Air France> (12)
|
||||
# 2 londON_StockhOlm 10065.0 [24, 43, 87] (British Airways. )
|
||||
# 3 Budapest_PaRis NaN [13] 12. Air France
|
||||
# 4 Brussels_londOn 10085.0 [67, 32] "Swiss Air"
|
||||
# 缺失值常用nan表示
|
||||
|
||||
# interpolate() 是 Pandas 中的一个方法,用于填补缺失值(NaN)。
|
||||
# 它使用插值算法推测缺失数据点的值,默认情况下采用线性插值(通过连接已知点的直线来估算未知点的值)
|
||||
# astype(int) 方法将插值后的 FlightNumber 列的所有数据转换为整数类型。
|
||||
df['FlightNumber'] = df['FlightNumber'].interpolate().astype(int)
|
||||
print(df)
|
||||
# From_To FlightNumber RecentDelays Airline
|
||||
# 0 LoNDon_paris 10045 [23, 47] KLM(!)
|
||||
# 1 MAdrid_miLAN 10055 [] <Air France> (12)
|
||||
# 2 londON_StockhOlm 10065 [24, 43, 87] (British Airways. )
|
||||
# 3 Budapest_PaRis 10075 [13] 12. Air France
|
||||
# 4 Brussels_londOn 10085 [67, 32] "Swiss Air"
|
||||
|
||||
temp = df['From_To'].str.split("_", expand=True)
|
||||
print(temp)
|
||||
# 0 1
|
||||
# 0 LoNDon paris
|
||||
# 1 MAdrid miLAN
|
||||
# 2 londON StockhOlm
|
||||
# 3 Budapest PaRis
|
||||
# 4 Brussels londOn
|
||||
|
||||
# 赋予为列From与To
|
||||
temp.columns = ['From', 'To']
|
||||
print(temp)
|
||||
# From To
|
||||
# 0 LoNDon paris
|
||||
# 1 MAdrid miLAN
|
||||
# 2 londON StockhOlm
|
||||
# 3 Budapest PaRis
|
||||
# 4 Brussels londOn
|
||||
|
||||
# 处理首字母
|
||||
temp['From'] = temp['From'].str.capitalize()
|
||||
temp['To'] = temp['To'].str.capitalize()
|
||||
print(temp)
|
||||
# From To
|
||||
# 0 London Paris
|
||||
# 1 Madrid Milan
|
||||
# 2 London Stockholm
|
||||
# 3 Budapest Paris
|
||||
# 4 Brussels London
|
||||
|
||||
|
||||
# 'From_To':
|
||||
# 这是你想要删除的列名。在这个例子中,删除的是名为 'From_To' 的列。
|
||||
# axis 参数指定是删除行还是列:
|
||||
# axis=0 表示删除行(按行操作)。
|
||||
# axis=1 表示删除列(按列操作)。
|
||||
# inplace=True 表示直接在原数据框 df 上进行操作,修改会生效并且不会返回新的数据框。即,不需要重新赋值给 df,它会在原地修改数据框。
|
||||
# 如果设置为 inplace=False(默认值),则 drop() 方法会返回一个删除指定列的新的数据框,而原数据框 df 不会被改变。
|
||||
df.drop('From_To', axis=1, inplace=True)
|
||||
print(df)
|
||||
# FlightNumber RecentDelays Airline
|
||||
# 0 10045 [23, 47] KLM(!)
|
||||
# 1 10055 [] <Air France> (12)
|
||||
# 2 10065 [24, 43, 87] (British Airways. )
|
||||
# 3 10075 [13] 12. Air France
|
||||
# 4 10085 [67, 32] "Swiss Air"
|
||||
|
||||
|
||||
# 合并到df
|
||||
df[['From', 'To']] = temp
|
||||
print(df)
|
||||
# FlightNumber RecentDelays Airline From To
|
||||
# 0 10045 [23, 47] KLM(!) London Paris
|
||||
# 1 10055 [] <Air France> (12) Madrid Milan
|
||||
# 2 10065 [24, 43, 87] (British Airways. ) London Stockholm
|
||||
# 3 10075 [13] 12. Air France Budapest Paris
|
||||
# 4 10085 [67, 32] "Swiss Air" Brussels London
|
||||
|
||||
# 去除其他字符
|
||||
# r'([a-zA-Z\s]+)' 是正则表达式,用于匹配字符串中连续的字母和空格
|
||||
# strip()去除首位空格,但是中间不管
|
||||
df['Airline'] = df['Airline'].str.extract(r'([a-zA-Z\s]+)', expand=False).str.strip()
|
||||
print(df)
|
||||
# FlightNumber RecentDelays Airline From To
|
||||
# 0 10045 [23, 47] KLM London Paris
|
||||
# 1 10055 [] Air France Madrid Milan
|
||||
# 2 10065 [24, 43, 87] British Airways London Stockholm
|
||||
# 3 10075 [13] Air France Budapest Paris
|
||||
# 4 10085 [67, 32] Swiss Air Brussels London
|
||||
|
||||
|
||||
delays = df['RecentDelays'].apply(pd.Series)
|
||||
print(delays)
|
||||
# 0 1 2
|
||||
# 0 23.0 47.0 NaN
|
||||
# 1 NaN NaN NaN
|
||||
# 2 24.0 43.0 87.0
|
||||
# 3 13.0 NaN NaN
|
||||
# 4 67.0 32.0 NaN
|
||||
delays.columns = ['delay_%s' % i for i in range(1, len(delays.columns)+1)]
|
||||
df = df.drop('RecentDelays', axis=1).join(delays, how='left')
|
||||
# join(delays, how='left')的主体似乎是dalays来区分左右
|
||||
print(df)
|
||||
# FlightNumber Airline From ... delay_1 delay_2 delay_3
|
||||
# 0 10045 KLM London ... 23.0 47.0 NaN
|
||||
# 1 10055 Air France Madrid ... NaN NaN NaN
|
||||
# 2 10065 British Airways London ... 24.0 43.0 87.0
|
||||
# 3 10075 Air France Budapest ... 13.0 NaN NaN
|
||||
# 4 10085 Swiss Air Brussels ... 67.0 32.0 NaN
|
||||
|
||||
|
||||
# 将delay_i列的控制nan都填为自身的平均值。fillna自如其意
|
||||
for i in range(1, 4):
|
||||
df[f'delay_{i}'] = df[f'delay_{i}'].fillna(np.mean(df[f'delay_{i}']))
|
||||
print(df)
|
||||
# FlightNumber Airline From ... delay_1 delay_2 delay_3
|
||||
# 0 10045 KLM London ... 23.00 47.000000 87.0
|
||||
# 1 10055 Air France Madrid ... 31.75 40.666667 87.0
|
||||
# 2 10065 British Airways London ... 24.00 43.000000 87.0
|
||||
# 3 10075 Air France Budapest ... 13.00 40.666667 87.0
|
||||
# 4 10085 Swiss Air Brussels ... 67.00 32.000000 87.0
|
||||
|
||||
# 增加一行相同的
|
||||
df = df._append(df.loc[df['FlightNumber'] == 10085, :], ignore_index=True)
|
||||
print(df)
|
||||
# [5 rows x 7 columns]
|
||||
# FlightNumber Airline From ... delay_1 delay_2 delay_3
|
||||
# 0 10045 KLM London ... 23.00 47.000000 87.0
|
||||
# 1 10055 Air France Madrid ... 31.75 40.666667 87.0
|
||||
# 2 10065 British Airways London ... 24.00 43.000000 87.0
|
||||
# 3 10075 Air France Budapest ... 13.00 40.666667 87.0
|
||||
# 4 10085 Swiss Air Brussels ... 67.00 32.000000 87.0
|
||||
# 5 10085 Swiss Air Brussels ... 67.00 32.000000 87.0
|
||||
|
||||
|
||||
# 去重
|
||||
df = df.drop_duplicates()
|
||||
print(df)
|
||||
# FlightNumber Airline From ... delay_1 delay_2 delay_3
|
||||
# 0 10045 KLM London ... 23.00 47.000000 87.0
|
||||
# 1 10055 Air France Madrid ... 31.75 40.666667 87.0
|
||||
# 2 10065 British Airways London ... 24.00 43.000000 87.0
|
||||
# 3 10075 Air France Budapest ... 13.00 40.666667 87.0
|
||||
# 4 10085 Swiss Air Brussels ... 67.00 32.000000 87.0
|
||||
```
|
||||
|
||||
## 数据的规约
|
||||
|
||||
min-max规约的表达式形如:
|
||||
$$
|
||||
x_n=\frac {max(x)−min(x)}{x−min(x)}
|
||||
$$
|
||||
这一操作的目的是为了消除量纲影响,所有的属性都被规约到[0,1]的范围内,数据的偏差不会那么大。但是如果出现异常值,比如非常大的数值,那么这个数据的分布是有偏的。为了对数据的分布进行规约,还会使用到另一个常用的方法就是Z-score规约:
|
||||
$$
|
||||
x_n=\frac {x− \bar x}{std(x)}
|
||||
$$
|
||||
本质上,一列数据减去其均值再除以标准差,如果这一列数据近似服从正态分布,这个过程就是化为标准正态分布的过程。Z-score规约和min-max规约往往不是二者取其一,有时候两个可以组合起来用。
|
||||
|
||||
## 初探数据分析
|
||||
|
||||
### 分析方法
|
||||
|
||||
回归分析:
|
||||
|
||||
对数据进行线性回归,看相关度的系数即可分析
|
||||
|
||||
分类分析:
|
||||
|
||||
逻辑分类法
|
||||
|
||||
### 假设检验
|
||||
|
||||
正态性检验:于参数检验比非参数检验更灵敏,因此一旦数据是正态分布的,我们应该使用参数检验,三种方法判断数据的正态性:可视化判断-正态分布概率图;Shapiro-Wilk检验;D'Agostino's K-squared检验。
|
||||
|
||||
画图:分位数一一对应即可
|
||||
|
||||
1)单组样本均值假定的检验
|
||||
|
||||
单样本t检验与wilcoxon检验。
|
||||
|
||||
2)两组样本的均值相等性检验
|
||||
|
||||
若两个样本的总体都服从正态分布,那么我们可以使用双样本t检验。如果不服从正态分布,则可以使用Mannwhitneyu秩和检验,Mannwhitneyu秩和检验是一种非参数检验。
|
||||
|
||||
先进行两组数据的方差齐性检验
|
||||
|
||||
若在显著性水平0.05下,不能拒绝两组样本方差相等的假设(p=0.8277),因此需要使用方差相等的t检验
|
||||
|
||||
在进行两组间均值比较的时候,有一种特殊情况——两个样本“故意”不独立。这种情况多出现两个样本分别为同一个受试个体不同时间的受试结果,这两个样本是“成对”的,是彼此紧密相连的。对这样两个样本进行均值比较检验,就是成对检验
|
||||
28
零碎的知识/设置ipv4自动设置.md
Normal file
28
零碎的知识/设置ipv4自动设置.md
Normal file
@@ -0,0 +1,28 @@
|
||||
nmcli connection show 【连接名称】
|
||||
|
||||
ipv4.method: manual
|
||||
说明不是自动
|
||||
nmcli connection modify netplan-eth0 ipv4.method auto
|
||||
设置自动
|
||||
sudo nmcli connection modify netplan-eth0 ipv4.addresses "" ipv4.gateway ""
|
||||
清空原设置静态ip
|
||||
sudo nmcli connection down netplan-eth0 && sudo nmcli connection up netplan-eth0
|
||||
重新连接
|
||||
|
||||
|
||||
nano /etc/ssh/sshd_config
|
||||
ctrl o保存
|
||||
CTRL x 退出
|
||||
|
||||
sudo systemctl restart sshd
|
||||
重启
|
||||
sudo systemctl status sshd
|
||||
|
||||
alist
|
||||
|
||||
rclone
|
||||
|
||||
openwebui
|
||||
|
||||
ssh 聚合
|
||||
jshell
|
||||
17
零碎的知识/设置代理.md
Normal file
17
零碎的知识/设置代理.md
Normal file
@@ -0,0 +1,17 @@
|
||||
# 设置代理
|
||||
|
||||

|
||||
cyy@ubuntu:~$ export https_proxy="http://192.168.137.1:7890"
|
||||
cyy@ubuntu:~$ export http_proxy="http://192.168.137.1:7890"
|
||||
|
||||
win端 win+r
|
||||
ipconfig
|
||||
|
||||
以太网适配器 VMware Network Adapter VMnet8:
|
||||
|
||||
连接特定的 DNS 后缀 . . . . . . . :
|
||||
本地链接 IPv6 地址. . . . . . . . : fe80::3191:d562:c375:6db6%39
|
||||
IPv4 地址 . . . . . . . . . . . . : 192.168.137.1
|
||||
子网掩码 . . . . . . . . . . . . : 255.255.255.0
|
||||
默认网关. . . . . . . . . . . . . :
|
||||
|
||||
Reference in New Issue
Block a user